
TIL_12월 8일
이미지 증강
12월 8일 목요일
이미지 데이터 증강이란?
: 영상 기반의 인공지능 모델을 사용하여 객체를 검출 및 인식하기 위해 이미지 데이터를 수집하여 CNN을 거쳐 훈련시키는 것입니다.
이 때 이미지 데이터의 수는 인식률을 높이기 위해선 객체당 수 백장, 수 천, 수 만장까지 필요로 합니다. 다양한 오픈소스에서 제공하는 데이터를 가져와 활용하면 쉽게 데이터셋을 구축할 수 있지만 내가 원하는 이미지 데이터가 존재하지 않을 때, 또한 이미지 수가 부족한 상황이 매우 드물지만 마주치게 됩니다.
이 때, 이미지 데이터 증강을 통해 다양한 유형의 학습 이미지 데이터 양을 늘리는 것입니다.
학습 이미지의 개수를 늘리는 것이 아니라 학습 시 마다 개별 원본 이미지를 변형해서 학습하는 것입니다.
데이터 증강 종류
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#cv2.imread는 이미지를 RGB가 아닌 BGR로 받아오기 때문에 바꿔 주어야함.
image = cv2.cvtColor(cv2.imread('data/img.jpg'), cv2.COLOR_BGR2RGB)
plt.imshow(image)

#augmentation이 적용된 image들을 시각화 해주는 함수
def show_aug_image(image, generator, n_images=4):
# ImageDataGenerator는 여러개의 image를 입력으로 받기 때문에 4차원으로 입력 해야함.
image_batch = np.expand_dims(image, axis=0)
# featurewise_center or featurewise_std_normalization or zca_whitening 가 True일때만 fit 해주어야함
generator.fit(image_batch)
# flow로 image batch를 generator에 넣어주어야함.
data_gen_iter = generator.flow(image_batch)
fig, axs = plt.subplots(nrows=1, ncols=n_images, figsize=(15, 8))
for i in range(n_images):
#generator에 batch size 만큼 augmentation 적용(매번 적용이 다름)
aug_image_batch = next(data_gen_iter)
aug_image = np.squeeze(aug_image_batch)
aug_image = aug_image.astype('int')
axs[i].imshow(aug_image)
```## ****ImageDataGenerator 변환 유형****
## **Flip**
- 좌우 반전: horizontal_flip = True
```python
# 좌우반전
data_generator = ImageDataGenerator(horizontal_flip=True)
show_aug_image(image, data_generator, n_images=4)

- 상하 반전: vertical_flip = True
# 상하반전
data_generator = ImageDataGenerator(vertical_flip=True)
show_aug_image(image, data_generator, n_images=4)

Rotation
- rotation_range = x
- 임의의 -x ~ +x 사이 회전
- 빈 공간은 fill_mode로 채워짐, default는 nearest
# 60도 회전
data_generator = ImageDataGenerator(rotation_range=60)
show_aug_image(image, data_generator, n_images=4)

Zoom
- zoom_range = [0.5, 1.5]
- 1보다 작은 값은 확장
- 1보다 큰 값은 축소(빈 공간은 fill_mode로 채워짐, default는 nearest)
# 확대
data_generator = ImageDataGenerator(zoom_range=[0.5, 0.9])
show_aug_image(image, data_generator, n_images=4)
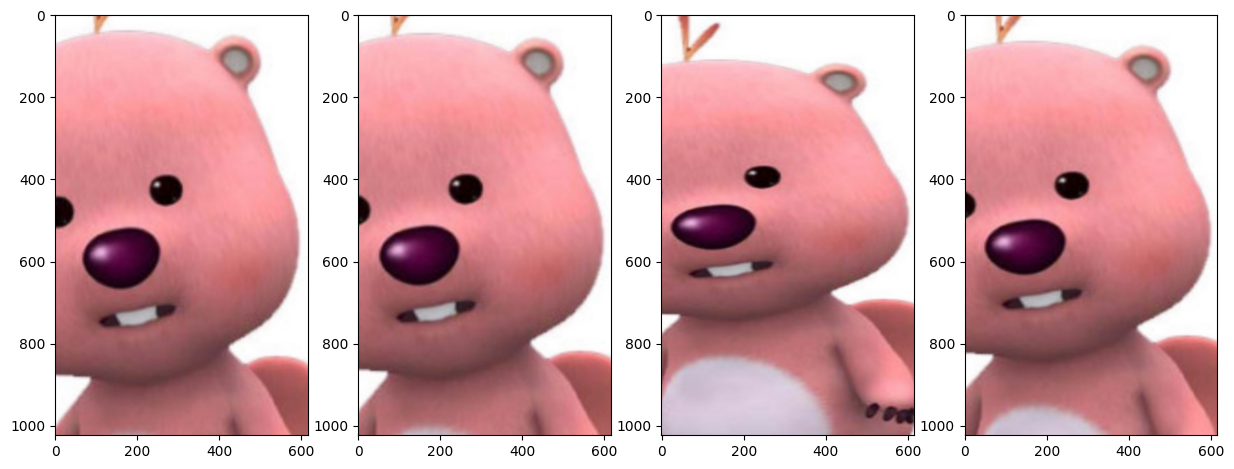
# 축소 후 채우기 -> cval=0 검정, cval=255 흰색
data_generator = ImageDataGenerator(zoom_range=[1.1, 1.5], fill_mode='constant', cval=0)
show_aug_image(image, data_generator, n_images=4)

Shift
- 좌우 이동: width_shift_range = 0.2
- 상하 이동: height_shift_range = 0.2
- 0~1사이 값
- 빈 공간은 fill_mode로 채워짐, default는 nearest
# fill_mode='nearest' -> 비어있는 곳의 가까운 픽셀로 채우기
data_generator = ImageDataGenerator(width_shift_range=0.4, fill_mode='nearest')
show_aug_image(image, data_generator, n_images=4)

# fill_mode='reflect' -> 비어있는 영역의 근처 공간을 반전시켜 채우기
data_generator = ImageDataGenerator(width_shift_range=0.4, fill_mode='reflect')
show_aug_image(image, data_generator, n_images=4)

# fill_mode='wrap' -> 비어있는 영역의 근처 공간을 그대로 가져와 채우기
data_generator = ImageDataGenerator(width_shift_range=0.4, fill_mode='wrap')
show_aug_image(image, data_generator, n_images=4)

# fill_mode='constant', cval=0 -> cval로 설정해준 값으로 채우기 0이면 검정, 255면 흰색
data_generator = ImageDataGenerator(width_shift_range=0.4, fill_mode='constant', cval=0)
show_aug_image(image, data_generator, n_images=4)

Shear
- shear_range = 45
- X축 또는 y축 중심으로 0~45도 사이 변환
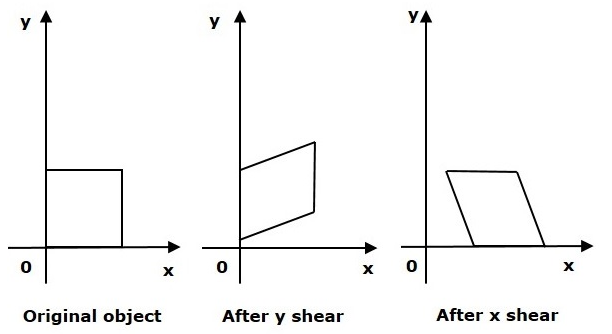
# 눕히기
data_generator = ImageDataGenerator(shear_range=45)
show_aug_image(image, data_generator, n_images=4)

Bright
- brightness_range = (0.1, 0.9)
- 밝기 조절, 0~1사이 값 입력, 0에 가까울수록 어둡고, 1에 가까울수록 밝음
# 밝기 조절
data_generator = ImageDataGenerator(brightness_range=(0.1, 0.9))
show_aug_image(image, data_generator, n_images=4)

# 밝기조절
data_generator = ImageDataGenerator(brightness_range=(1.0, 2.0))
show_aug_image(image, data_generator, n_images=4)

Channel Shift
- channel_shift_range = x
- R, G, B Pixel값을 -x ~ x 사이의 임의의 값을 더하여 변환, 0보다 작으면 0, 255보다 크면 255로 초기화
# RGB 값 변경 -> channel_shift_range 값으로 지정해준 범위안에 값으로 변경
data_generator = ImageDataGenerator(channel_shift_range=255)
show_aug_image(image, data_generator, n_images=4)

Nomalization
- featurewise_center=True, 각 R, G, B Pixel 값에서 개별 채널 별 평균 Pixel값을 빼서 평균이 0이 되게 유지
- featurewise_std_normalization=True 각 R, G, B Pixel값에서 개별 채널 별 표준 편차 Pixel값을 나눈다.
- rescale = 1/255.0. 딥러닝은 입력이 비교적 작은 값을 선호하므로 0~255 -> 0~1
증강 시 유의사항
1️⃣ 크롭이나 확대 : 노이즈 확대 및 크롭시 학습에 문제
2️⃣ 회전, 반전 : 6을 180도 돌리면 완전히 다른 의미인 9가 되기 때문에 이런 숫자 이미지는 돌리지 않는다.
3️⃣ 색상 변경 : 색상이 중요한 이미지(신호등-안전과 직결, 옐로/레드 카드 등)일 경우 색상 반전 혹은 변경을 하지 않는다
4️⃣ train set에만 적용 : 현실세계 문제를 푼다고 가정했을 때 현실세계 이미지가 들어왔을 때 증강해주지 않고 들어온 이미지로 판단하기 때문에 train에만 사용
다른 모듈
1️⃣ Albumentations
소개
Albumentations : Fast and Flexible Image Augmentations
다른 image augmentation 관련 library들과 비교해서 가장 큰 특징은 빠르다는 점이며, numpy, OpenCV 등 여러 library들을 기반으로 optimization을 하였기 때문에 빠른 속도를 보여준다.
-ImageDataGenerator의 한계점 보완: ImageDataGenerator는 augmentation toolbox가 충분히 포괄적이거나 빠르지 않을 수 있다 → 더 빠르고 다양한 augmentation 도구
예시
import albumentations as A
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5)
A.RandomBrightnessContrast(p=0.2),
])
- Compose
A.RandomCrop(width=256, height=256): 입력 이미지를 받아 256 * 256 픽셀 크기의 랜덤 패치를 추출하여 다음 파이프라인의 증강 결과를 전달한다.A.HorizontalFlip(p=0.5): 거의 모든 증강에서 지원되는 특수 매개변수이다. 확대 적용 확률을 제어한다. p=0.5는 50%의 확률로 변환이 이미지를 수평으로 뒤집고 50%의 확률로 변환이 입력 이미지를 수정하지 않음을 의미한다.A.RandomBrighntessContrast(p=0.2): 20%의 확률로 이 증강은 수평플립으로 부터 받은 이미지의 밝기와 대비를 변경한다. 그리고 80%의 확률로 수신된 이미지를 변경하지 않고 유지한다.

2️⃣ Augmentor
특징
-파이썬 라이브러리
-전처리된 이미지 파일을 output이라는 폴더에 별도로 생성하여 저장
예시
pip install Augmentor # 1) 모듈 설치
import Augmentor # 2) 모듈 호출 및 파이프라인 구축
p = Augmentor.Pipeline("/path/to/images") # 이미지 파일이 들어있는 디렉토리를 설정
# 3) operation 추가(접돌땡)
# Augmentor에서 제공하는 main features
# perspective skewing 비스듬히 보기
p.skew_tilt()
p.skew_left_right()
p.skew_top_bottom()
p.skew_corner()
p.skew()
# elastic distortions #왜곡
p.random_distortion(probability=1, grid_width=4, grid_height=4, magnitude=8)
# rotating 회전
p.rotate(probability=0.7, max_left_rotation=10, max_right_rotation=10)
rotate()
rotate90()
rotate180()
rotate270()
rotate_random_90()
# shearing 기울이기
shear()
# cropping 자르기
p.crop_centre()
p.crop_by_size()
p.crop_random()
# mirroring 접기
flip_left_right()
flip_top_bottom()
flip_random()
# 4) p.sample(num)로 증강할 이미지 데이터 개수 설정